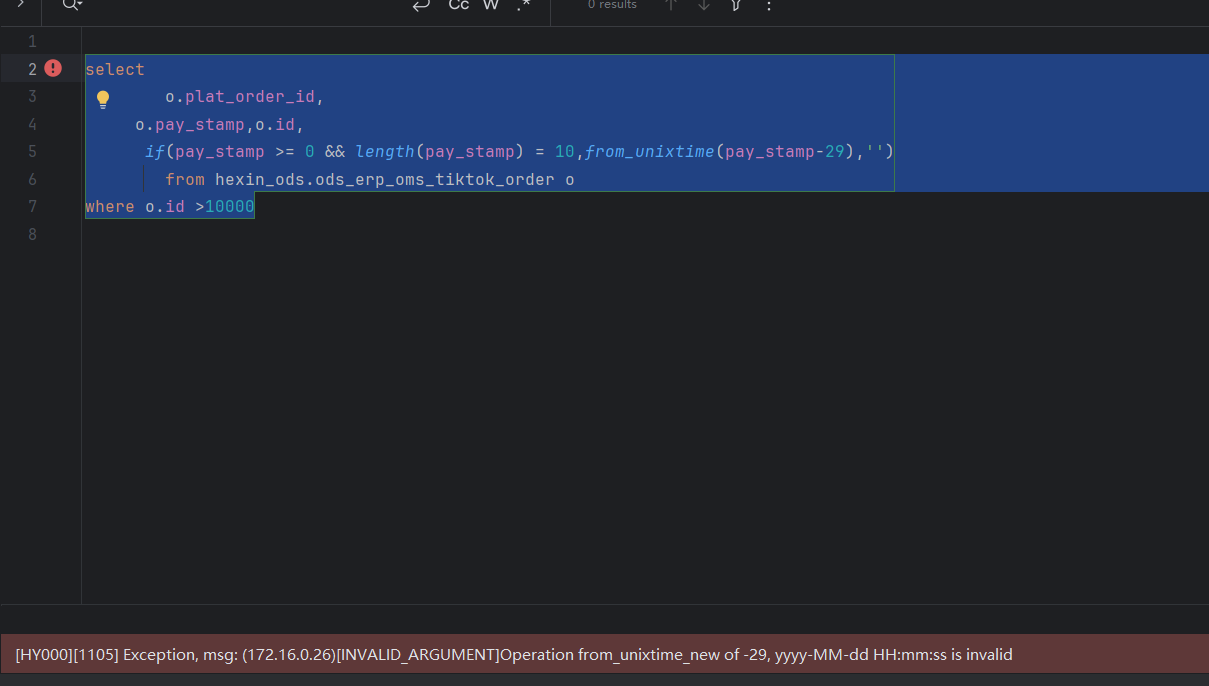
SQL
select
o.plat_order_id,
o.pay_stamp,o.id,
if(pay_stamp >= 30,from_unixtime(pay_stamp-29),'')
from hexin_ods.ods_erp_oms_tiktok_order o
where o.id >10000
异常
[HY000][1105] Exception, msg: (172.16.0.26)[INVALID_ARGUMENT]Operation from_unixtime_new of -29, yyyy-MM-dd HH:mm:ss is invalid
验证及猜测
from_unixtime(if(...)) 能成功而 if(..., from_unixtime(...)) 失败,这直接证明了问题的核心在于 表达式求值顺序(Evaluation Order) 和 向量化引擎的参数预先计算机制。
在 Doris 4.0 的向量化引擎中,IF 函数不再像传统行式引擎那样支持“短路求值”,而是采用“全量求值后选择”的策略。
EXPLAIN
- if(..., from_unixtime(...))
PLAN FRAGMENT 0
OUTPUT EXPRS:
plat_order_id[#75]
pay_stamp[#76]
id[#77]
" if(pay_stamp >= 30,from_unixtime(pay_stamp-29),'')[#78]"
PARTITION: HASH_PARTITIONED: id[#0]
""
HAS_COLO_PLAN_NODE: false
""
VRESULT SINK
MYSQL_PROTOCOL
""
0:VOlapScanNode(111)
" TABLE: hexin_ods.ods_erp_oms_tiktok_order(ods_erp_oms_tiktok_order), PREAGGREGATION: ON"
PREDICATES: ((id[#0] > 10000) AND (__DORIS_DELETE_SIGN__[#73] = 0))
partitions=1/1 (ods_erp_oms_tiktok_order)
" tablets=10/10, tabletList=1771689840857,1771689840859,1771689840861 ..."
" cardinality=5998695, avgRowSize=374.03387, numNodes=2"
pushAggOp=NONE
" final projections: plat_order_id[#4], pay_stamp[#60], id[#0], if((pay_stamp[#60] >= 30), from_unixtime((pay_stamp[#60] - 29)), '')"
final project output tuple id: 1
""
""
""
========== STATISTICS ==========
planned with unknown column statistics
- from_unixtime(if(...))
PLAN FRAGMENT 0
OUTPUT EXPRS:
plat_order_id[#75]
pay_stamp[#76]
id[#77]
" from_unixtime(if(pay_stamp >= 30,pay_stamp-29,0))[#78]"
PARTITION: HASH_PARTITIONED: id[#0]
""
HAS_COLO_PLAN_NODE: false
""
VRESULT SINK
MYSQL_PROTOCOL
""
0:VOlapScanNode(111)
" TABLE: hexin_ods.ods_erp_oms_tiktok_order(ods_erp_oms_tiktok_order), PREAGGREGATION: ON"
PREDICATES: ((id[#0] > 10000) AND (__DORIS_DELETE_SIGN__[#73] = 0))
partitions=1/1 (ods_erp_oms_tiktok_order)
" tablets=10/10, tabletList=1771689840857,1771689840859,1771689840861 ..."
" cardinality=5999294, avgRowSize=373.90082, numNodes=2"
pushAggOp=NONE
" final projections: plat_order_id[#4], pay_stamp[#60], id[#0], from_unixtime(if((pay_stamp[#60] >= 30), (pay_stamp[#60] - 29), 0))"
final project output tuple id: 1
""
""
""
========== STATISTICS ==========
planned with unknown column statistics
关于向量化引擎 IF 函数求值顺序的疑问
我们在使用 Doris 4.0.3 向量化引擎时发现一个问题:IF(condition, expr_true, expr_false) 会预先计算所有分支的参数,然后再根据条件选择结果。这导致:
- SQL 行为变更:3.12 版本能正常运行的 SQL(用 IF 保护函数参数)在 4.x 版本报错
- 潜在性能损耗:即使某行数据不满足条件,其对应的分支表达式仍会被计算
想请教几个问题:
Q1: 这是长期设计策略吗?
向量化引擎是否计划一直采用"全量求值"而非"短路求值"?
Q2: 设计目的是什么?
- 是为了 SIMD 批量处理效率?
- 还是为了简化执行器逻辑?
- 是否有相关的设计文档可以参考?
Q3: 性能影响有评估吗?
当 IF 条件过滤掉 50% 或 90% 的数据时,额外计算那些"最终不会使用"的分支,会带来多少 CPU 开销?是否有 benchmark 数据?
Q4: 是否有优化计划?
- 是否考虑对昂贵函数(如 UDF、正则、日期转换)实现懒加载/短路优化?
- 是否考虑让
from_unixtime()等函数对非法参数返回 NULL 而非抛异常?
我们的担忧
| 场景 | 行式引擎 | 向量化引擎 | 影响 |
|---|---|---|---|
| IF 保护函数参数 | ✅ 有效 | ❌ 无效 | SQL 需重写 |
| 过滤 90% 数据 | 只算 10% | 100% 都算 | 可能浪费 90% 计算 |
| 非法参数处理 | 返回 NULL | 抛异常 | 查询稳定性下降 |
希望社区能帮忙澄清一下设计意图,方便我们评估是否升级以及如何优化 SQL。谢谢!
