doris 版本3.0.8
- 使用routine load消费kafka到表中
- kafka数据为json
- 表结构,jsonstr用来存储整个json消息
( topicname varchar(500) NULL DEFAULT 'topic_name', jsonstr text NULL, data_day datev2 NULL DEFAULT CURRENT_DATE, input_time datetimev2 NULL DEFAULT CURRENT_TIMESTAMP ) - routine load参数
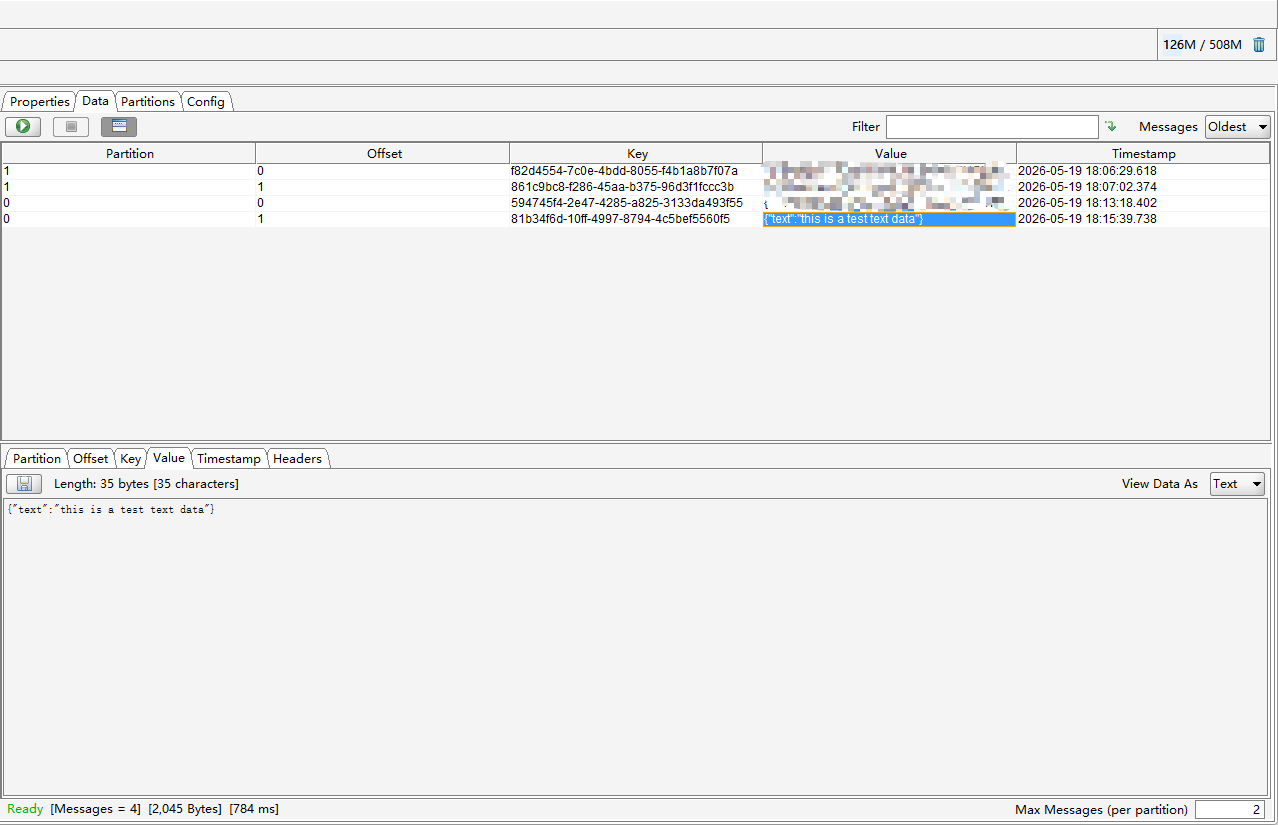
COLUMNS( jsonstr ) PROPERTIES( "desired_concurrent_number" = "2", "max_batch_interval" = "20", "format" = "json", "jsonpaths" = "[\"$\"]", "strip_outer_array" = "false", "strict_mode" = "false" ) - kafka消息:{"text":"this is a test text data"}
- 写到表里变成了[{"text":"this is a test text data"}]
配置该如何优化,将这个[]去掉
- 补充信息:之前是使用format=CSV,由于部分kafka没有进行压缩存在\t \n的格式符,\n导致一条消息中的一个json写入表后,被拆分成了多行,文档中查到routine load不支持修改默认换行符,所以改用了format=json,但是出现了这种问题
{
"max_batch_rows": "20000000",
"timezone": "Asia/Shanghai",
"send_batch_parallelism": "1",
"load_to_single_tablet": "false",
"delete": "*",
"current_concurrent_number": "2",
"partial_columns": "false",
"merge_type": "APPEND",
"exec_mem_limit": "2147483648",
"strict_mode": "false",
"jsonpaths": "[\"$.\"]", ----已生效
"max_batch_interval": "20",
"max_batch_size": "1073741824",
"fuzzy_parse": "false",
"escape": "0",
"enclose": "0",
"partitions": "*",
"columnToColumnExpr": "jsonstr",
"whereExpr": "*",
"desired_concurrent_number": "2",
"precedingFilter": "*",
"format": "json",
"max_error_number": "0",
"max_filter_ratio": "1.0",
"sequence_col": "*",
"json_root": "",
"strip_outer_array": "false",
"num_as_string": "false"
}

