每天会出现几次几分钟不能用的状态,监控中可以看到P99 查询延迟特别特别高
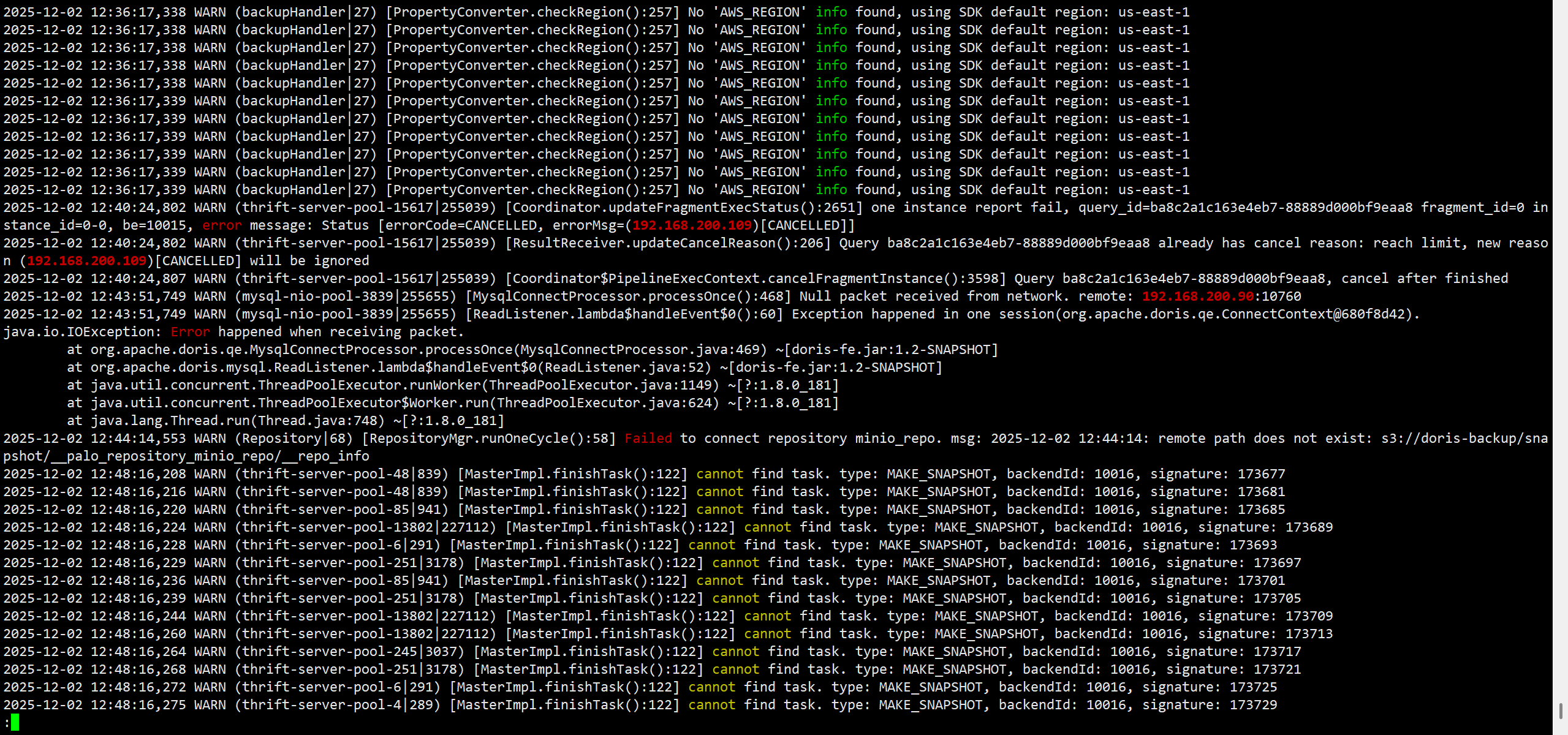
fe的192.168.200.108的warning日志:
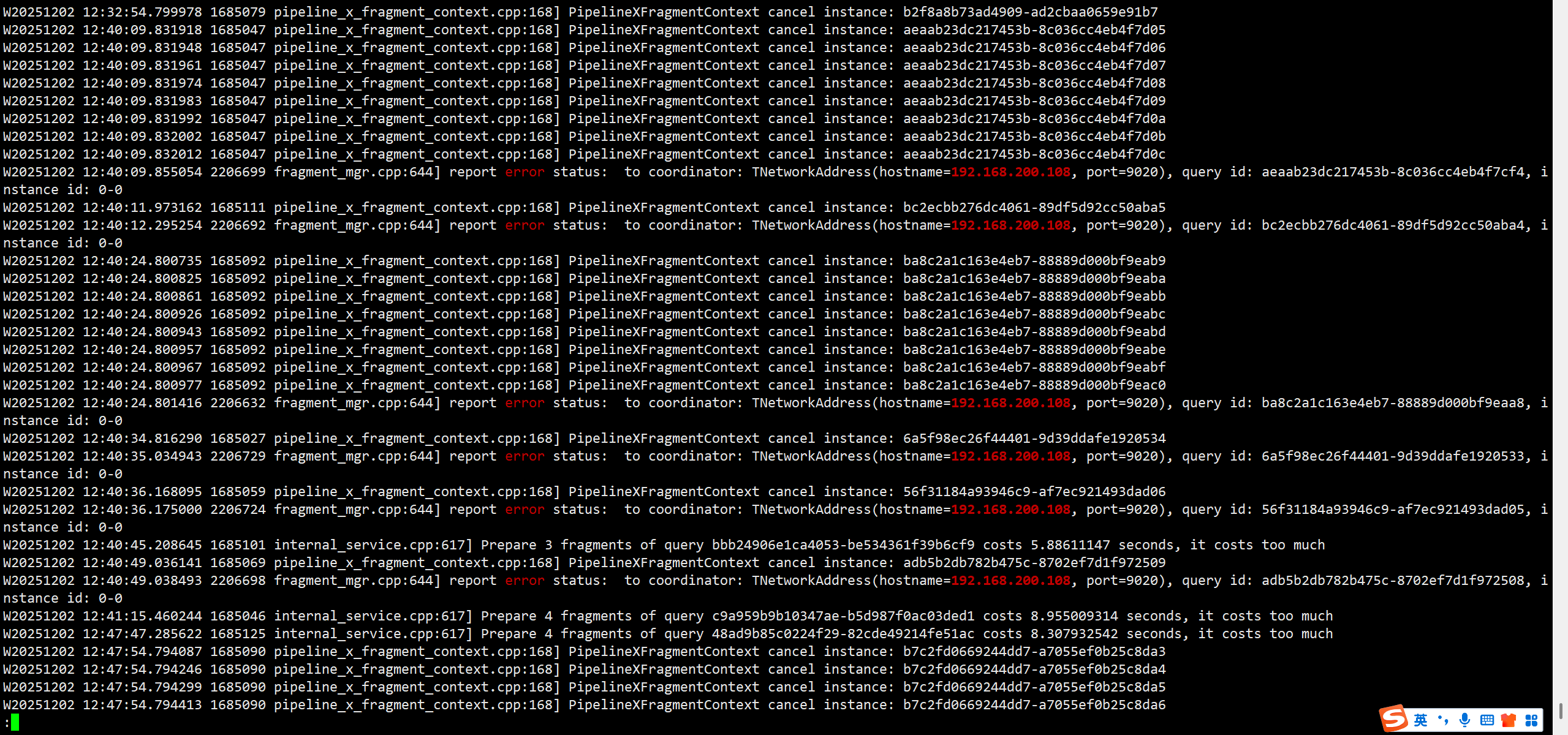
be的192.168.200.109的warning日志:
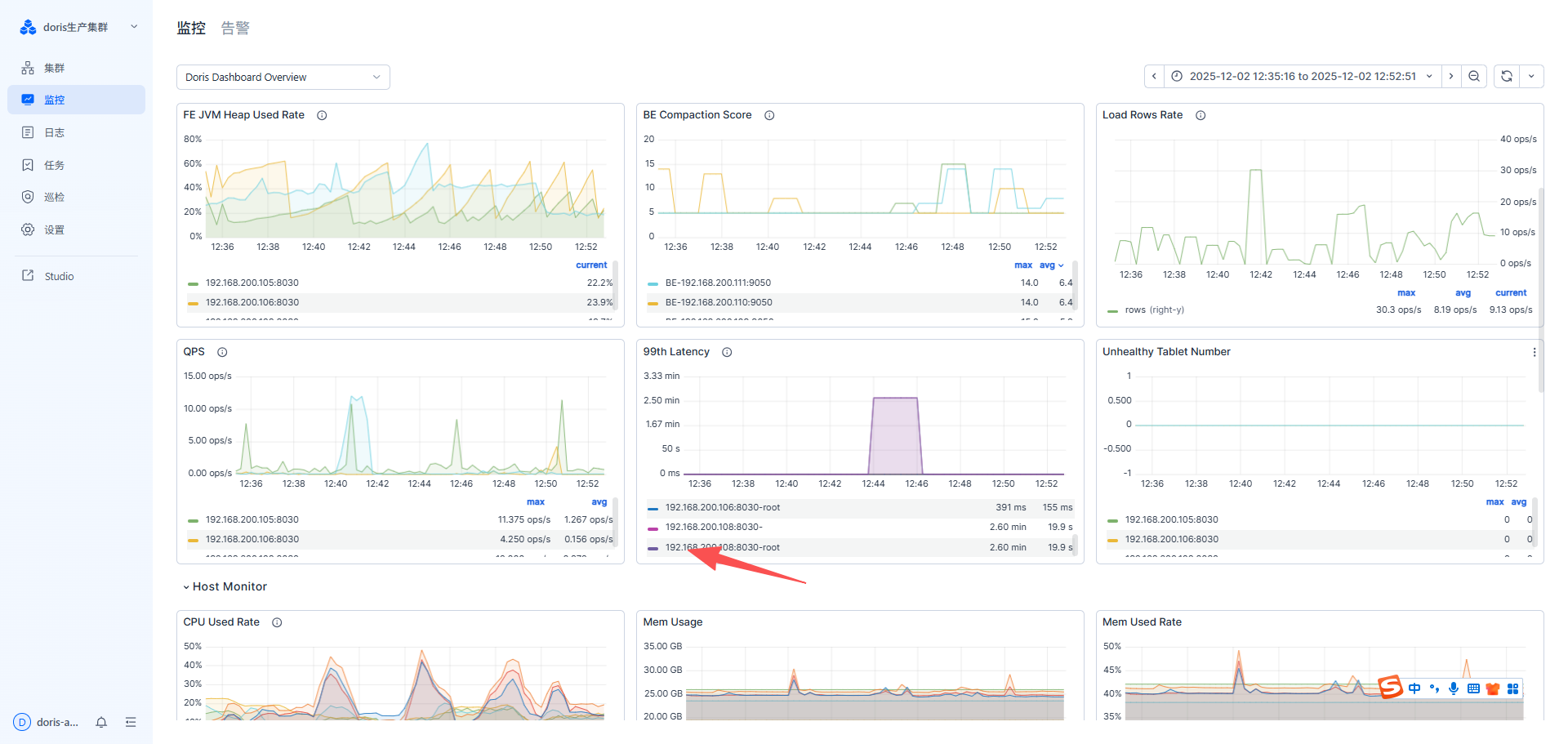
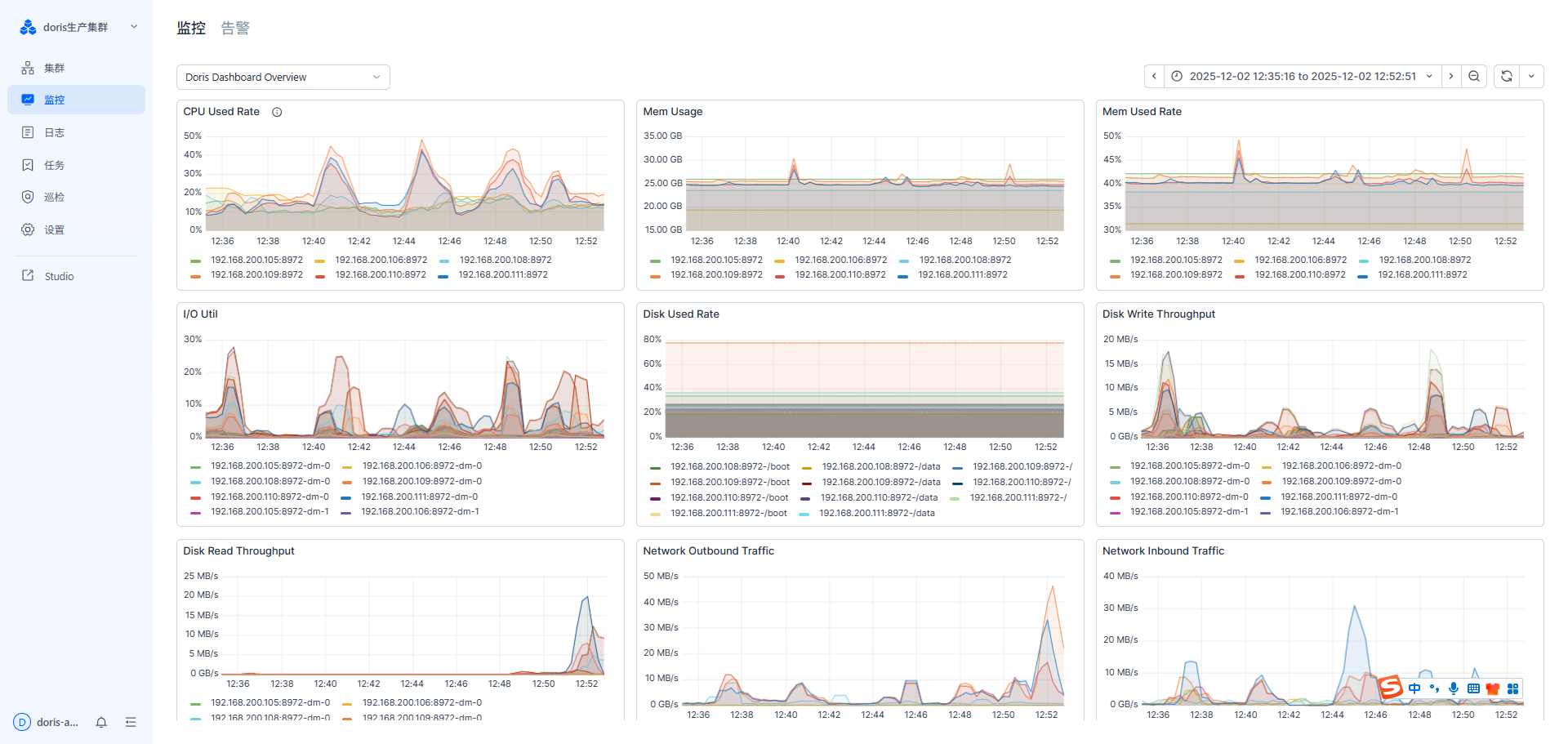
对应时间段的监控:
.....
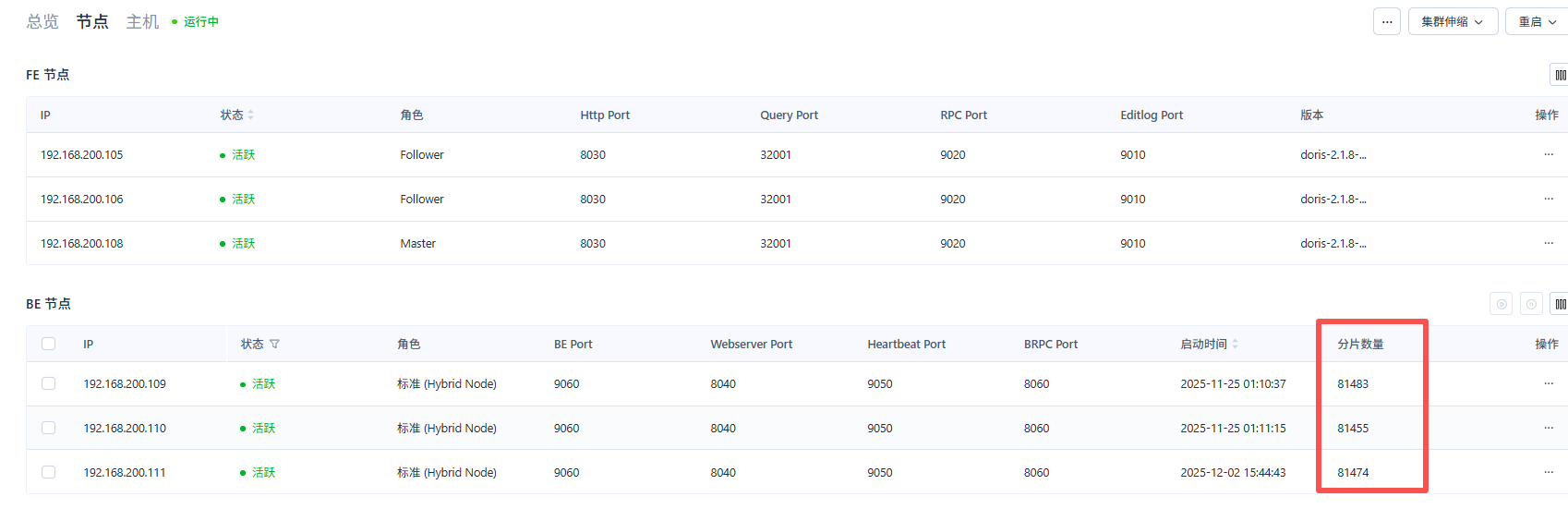
集群配置:
请问是因为tablet数量太多导致的吗?集群数据量大概在50G左右
每天会出现几次几分钟不能用的状态,监控中可以看到P99 查询延迟特别特别高
fe的192.168.200.108的warning日志:
be的192.168.200.109的warning日志:
对应时间段的监控:
.....
集群配置:
请问是因为tablet数量太多导致的吗?集群数据量大概在50G左右
从提供的信息来看
P99 查询延迟出现高延迟的时间段:12:44 —— 12:46
这个时间点,出现异常的监控指标有:FE JVM Heap、NetWork Inbound Traffic 这两个指标在相同的时间出现了异常。
是否有用到冷热分层,比如冷数据在对象上,扫到了冷数据导致?排查下是哪个sql,可以直接在审计日志中查下看看。
集群 50GB 数据,就有 8w多个 tablet,这个明显是不符合预期的,tablet太多了,可能建表不规范,或者有太多的空的历史分区,导致空tablet 异常的多,这种情况需要优化改善,否则之后BE常驻内存会越来越大,FE的元数据管理的压力也会变大。
可以加我主页微信一起看看~

