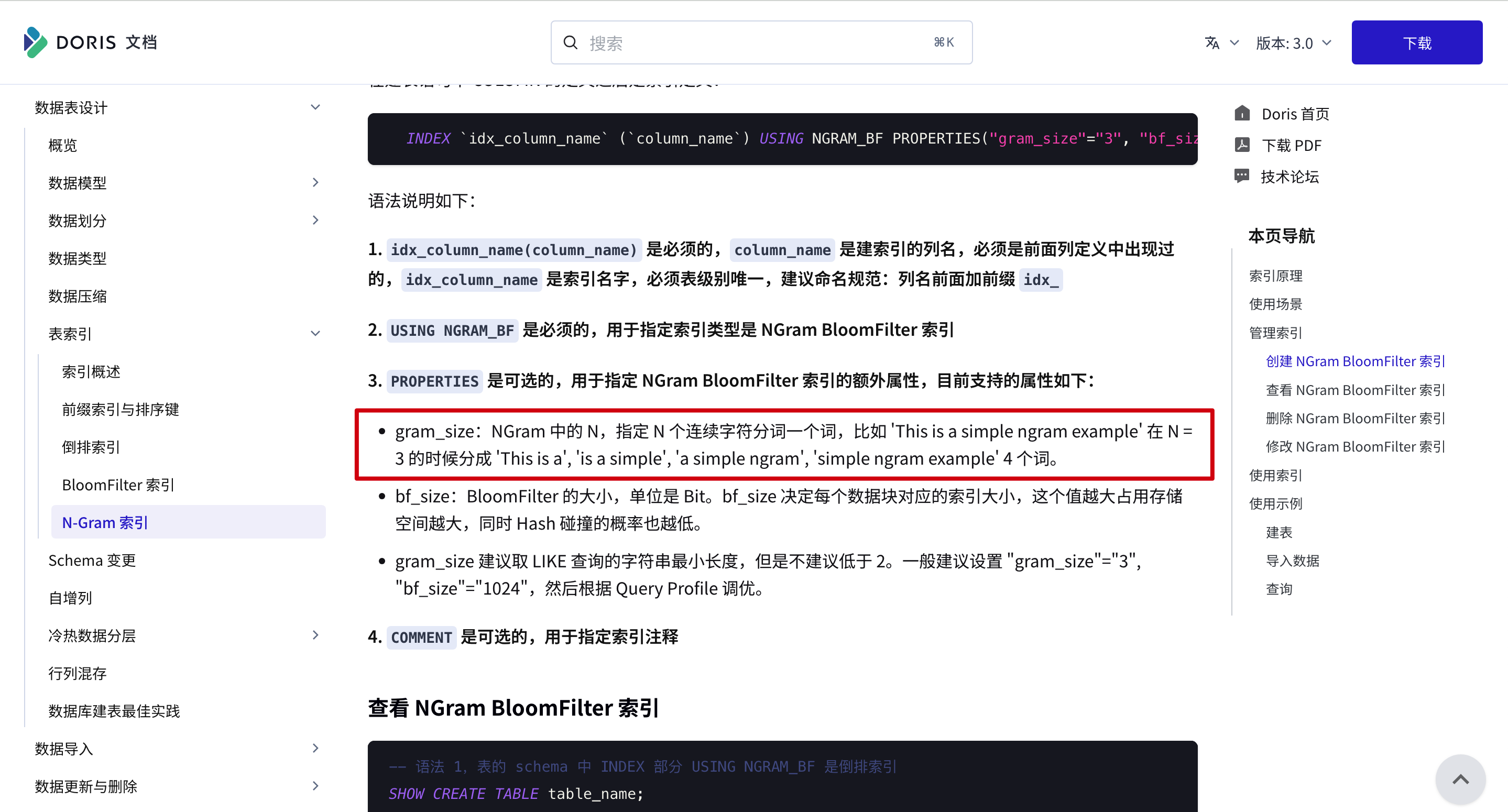
按文档的说法,N-Gram是“指定 N 个连续字符分词一个词”。
对于举例“This is a simple ngram example”,在N=3的情况,我理解按照字符级别分词,应该分为“Thi”、“his”、“is ”、“s a”、 ……。
但是文档中对于举例的内容是按word粒度进行分词的,在 N = 3 的时候分成 'This is a', 'is a simple', 'a simple ngram', 'simple ngram example' 4 个词。
如果按word级别分词,那是否就无法对 like '%his%' 这种搜索进行加速?