遇到一个技术问题,整体情况是利用spark采用spark-doris-connector的方式将hive表数据写入doris集群,下面描述背景和问题
【背景】
1)hive表的数据量级都在7、8亿级别,存储大概是30G左右,每个hive表按照表存储大小repartition为为500万/1000万/2000万条一个partition
2)写入sink参数设置为每一批次500000条,spark应用程序给的资源:executor-num为30、executor-memory为6G、executor-core为1、shuffle.partitions为200
3)2.1.4版本新doris集群总共5个fe、8个be,be节点的内存大小为208g、64核;老版本的Doris版本是2.0.2,5台fe、15台BE,be节点的配置是内存大小为128g、32核
4)所有的doris表均为unique模型;fe.conf新增配置参数qe_max_connection=20000,max_running_txn_num_per_db=15000;be.conf新增配置streaming_load_max_mb=102400,streaming_load_json_max_mb=512;数据写入时候BE所有节点的CPU都在20%以下,内存使用率也不高
【问题】
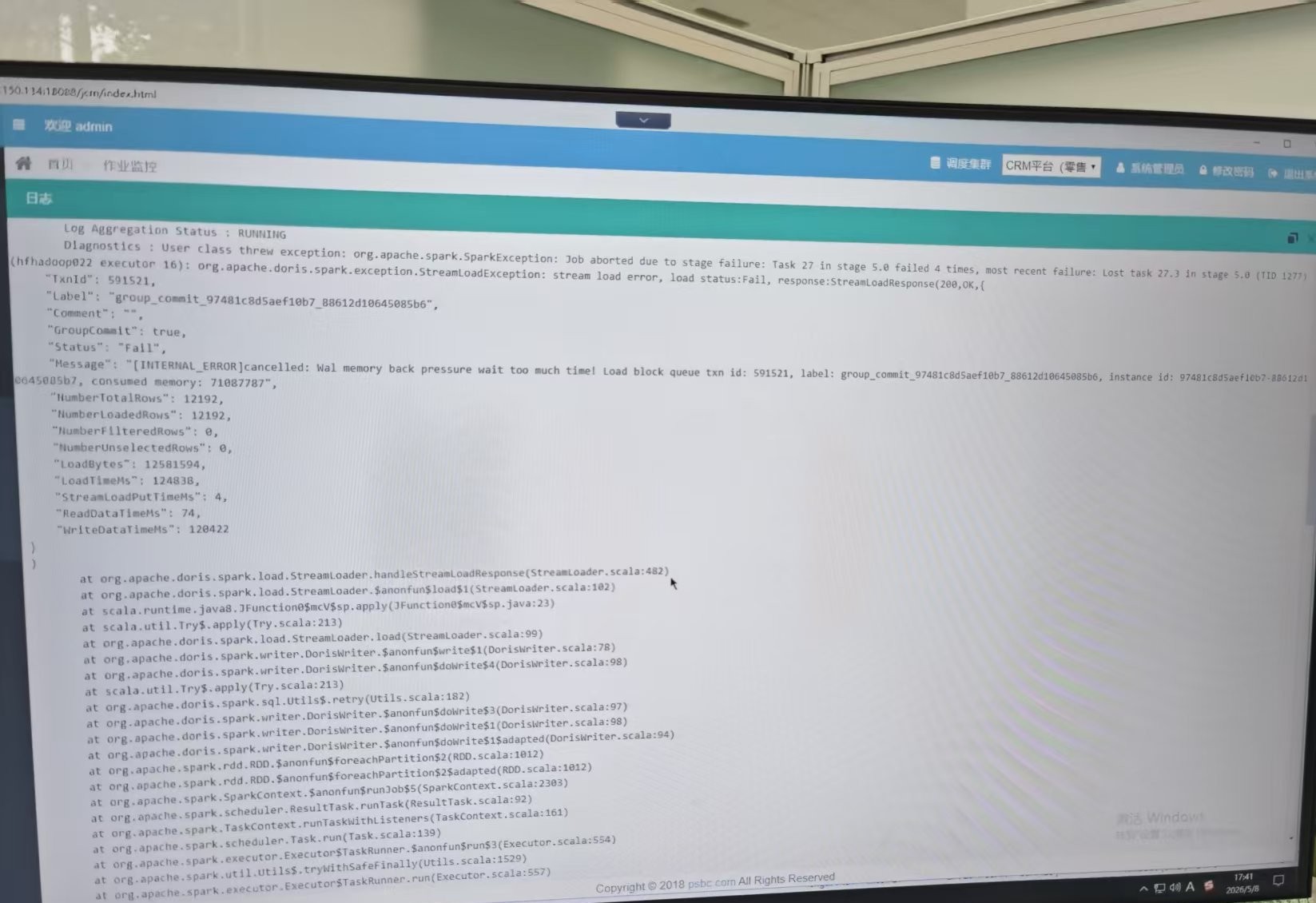
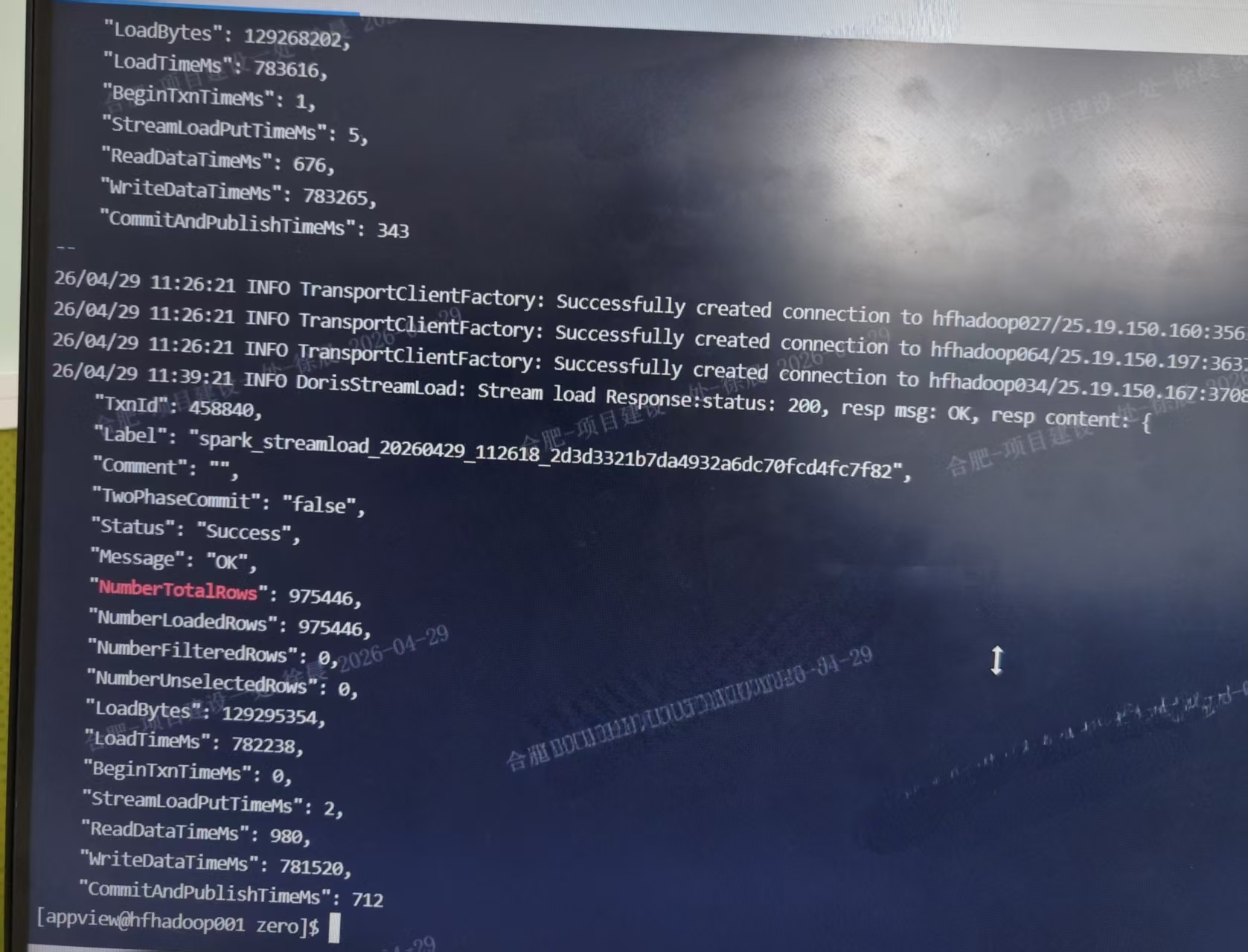
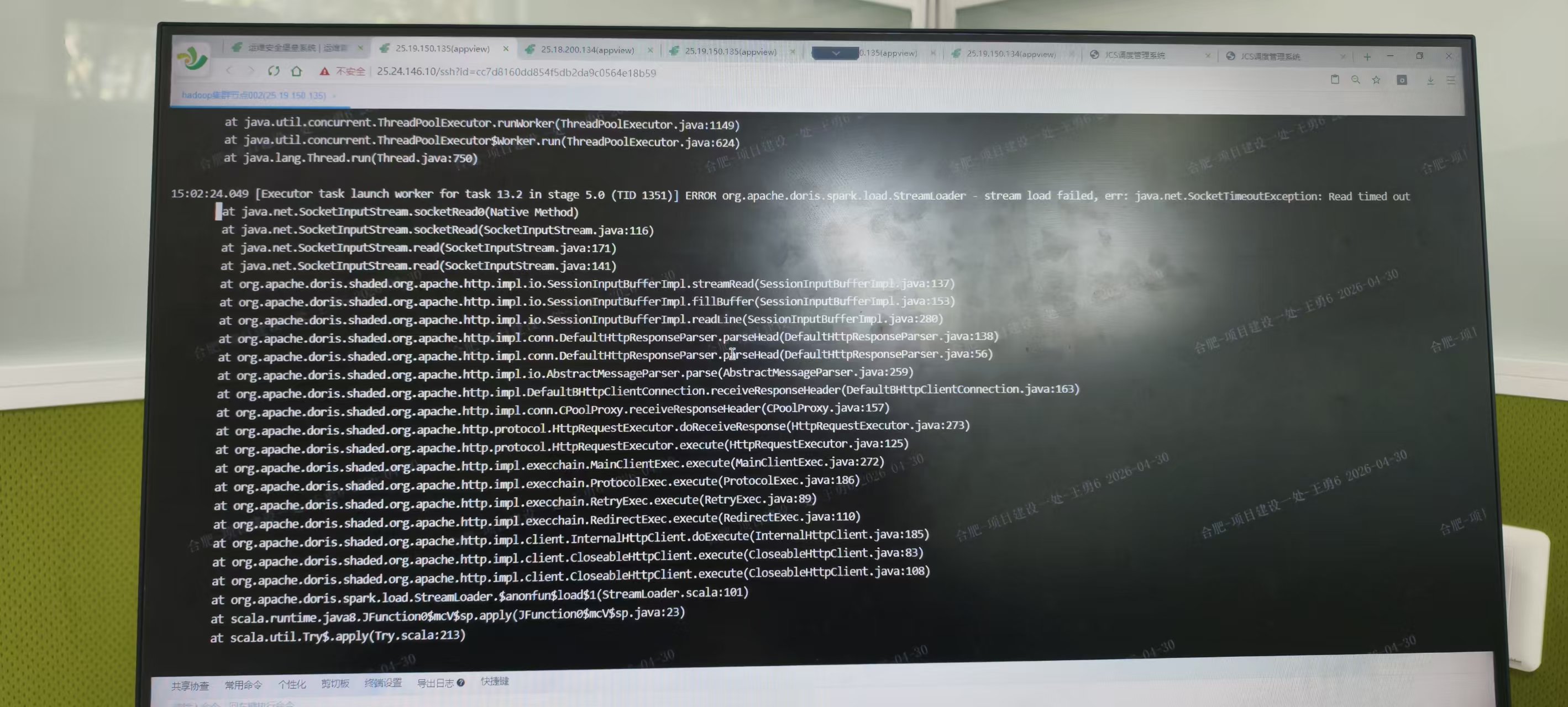
1)数据写入新版本2.1.4的doris集群时,当只有一个作业运行时候,大概8亿数据3、4个小时能写完,但是同时运行2个及以上数量的spark作业,就会现socketTimeOutException:read time out 异常,而且写入查看某一批次streamload的日志发现writedata耗时很长,100万数据需要1000秒左右的时间
2)调试过程中也实测了group-commit=async_mode参数,有时候作业能正常运行通过,数据能正常写入;但有时有报错提升[internal_error]wal memmory back presure wait to much time 异常,然后那一批次的数据就会丢数据。
3)老集群数据写入就没有上述问题,数据写入也很快,两者的使用场景完全一致
【思考】
1)是否需要增加BE节点;
2)sink参数或者新版doris集群的参数还能怎么优化;